Hashing
Hash
- 임의 크기의 key를 고정된 크기의 데이터로 변환시켜 저장하는 것
- 해시 자체는 고정된 길이의 데이터를 의미한다.
- 키에 대한 해시값을 구하는 과정을 해싱(hashing)이라 한다.
- 해시값 자체를 index로 사용하기 떄문에 시간 복잡도 O(1)로 매우 빠르다.
- 테이블 크기에 상관없이 데이터에 빠르게 접근 가능
- 모든 데이터를 살피지 않아도 검색과 삽입, 삭제 빠르게 수행
Hash 함수
- 키에 대한 해시 값을 만드는 함수 (알고리즘)
- 복잡하지 않은 알고리즘으로 구현되어 상대적으로 CPU, 메모리 리소스 등 자원을 덜 소모한다.
- 같은 입력 값에 대해서 같은 출력 값을 보장한다.
- 복호화 불가능 (단방향 암호화)
- 대표적으로
나눗셈법(division method), 곱셈법(multiplication method)이 있다.
좋은 해시 함수란? Simple, Uniform Hash
해시값은 해시값 범위(0 ~ size -1)를 동일한 확률로 (골고루, 균일하게) 나타낼 것
→ 충돌 확률 감소
각 해시값들은 서로 연관성 갖지 않고 독립적으로 생성될 것
→ 해시값들이 서로 연관되면 해당 해시 값이 나타나는 패턴, 순서가 존재할 수 있어 반복적인 해시 충돌 확률이 있기 떄문에 독립적으로 생성되는 것이 좋다.
<정리> 계산이 복잡하지 않고, 해시값의 충돌 없이 고르게 만들어내는 함수가 좋다.
Hash Table
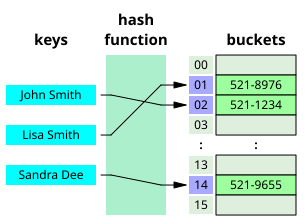 출처 : https://en.wikipedia.org/wiki/Hash_table
출처 : https://en.wikipedia.org/wiki/Hash_table
해싱을 사용하여 해시를 index 삼아 key, value로 데이터를 저장소(bucket, slot)에 저장하는 연관 배열 자료구조를 해시 테이블이라 한다. 기존 자료구조인 이진 탐색 트리나 배열에 비해 탐색, 삽입, 삭제 속도가 빠르다.
Associative Array, 연관 배열 구조
key 1개와 value 1개가 1:1로 연관되어 있는 자료구조다. 따라서 key를 이용하여 value를 찾을 수 있다.
해시 테이블에서 데이터를 저장하기 위해 key의 해시를 찾는다. 해시값을 인덱스로 적절한 위치의 저장소(bucket, slot)에 데이터를 저장한다.
Hash Collision
다른 키의 해시값이 동일한 상황을 의미한다.
Open Addressing, 개방 주소법
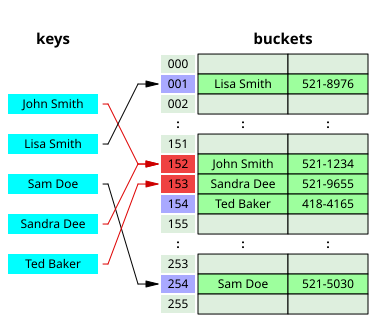 출처 : https://en.wikipedia.org/wiki/Hash_table
출처 : https://en.wikipedia.org/wiki/Hash_table
- 한 버킷 당 들어갈 수 있는 엔트리는 단 하나로 고정
- 데이터가 저장될 해시 버킷이 이미 사용 중인 경우 놀고 있는 다른 버킷을 찾아 데이터를 삽입한다.
- 해시 버킷을 찾을 때
Linear Probing, Quadratic Probing등의 방법을 사용한다. - 탐색 시간 복잡도 worst O(N), 버킷 사이즈 N
[장점]
- 인덱스에 직접 데이터를 저장하므로 메모리 효율이 좋다.
- 연속된 공간에 데이터를 저장하므로 캐싱 효율이 좋다.
- 그러나 버킷 사이즈 커질 수록 캐싱 효율 떨어져 적은 데이터에 적합
- 포인터가 필요 없어 구현이 용이하며, 포인터 접근에 필요한 시간이 없기 때문에 Separate Chaining 방식에 비해 성능이 좋다. (하지만 테이블 크기가 커지면 장점이 사라짐)
[단점]
- 정해진 해시 버킷 사이즈 이상 저장할 수 없다. (Chaining 방식은 데이터를 무한정 저장 가능)
- 클러스터링 문제
- 특정 영역에 데이터가 몰리는 상황이 발생 (해시 충돌 횟수 증가) → 성능 저하
- 데이터 삭제의 비효율
- 3개 데이터가 동일한 해시인 1이 나와서 연속적인 공간 1, 2, 3번 버킷에 저장됬을 때
- 2번 버킷이 삭제된다면 중간에 저장된 값들이 이가 빠지듯이 삭제될 것이고, 삭제된 값 이후의 값 3번 버킷을 검색할 때 어려움이 있을 수 있다.
- 별도로 삭제된 버킷을 관리해야 하므로 추가 메모리 공간 필요
슬롯의 상태 정보를 별도로 관리해야 하는 이유
9번째(idx : 2)를 삭제한다면, 9자리(idx : 2)의 상태를 DELETED로 바꾼다.
idx : 2를 검색할 때 해당 인덱스에 DELETED가 표시되어 충돌 발생을 의심하여 다음 칸을 검사한다. 만약 EMPTY 표시되었다면, 데이터가 존재하지 않는다 판단하여 탐색을 바로 종료할 것이다.- 상태를 별도로 저장하여 관리하면 검색에 지장이 없을 수 있지만, 빈 더미를 지나가기 때문에 탐색 시간은 비효율적.
Linear Probing, 선형 탐사법
- 충돌 발생 시 선형으로 순차 탐색하는 방법을 말한다. 인접한 버킷 슬롯을 탐색.
- Probing : 할당할 버킷을 탐색하는 것.
예를 들어
key % 7 해시 함수가 있다면, key 9를 저장할 때 idx 2에 저장한다. 이어서 해시 값이 2가 나오는 다른 데이터가 등장했을 때도 충돌로 idx 2에 저장할텐데, 옆자리가 비어 있으므로 idx 3에 저장한다.
[단점]
- 충돌이 발생할 수록 새로운 해시 값을 찾는 시간 증가 (성능 저하)
- Clustering, 군집화 문제
- 모든 키가 특정 영역에 몰려 채워지는 문제가 발생할 수 있다. (주변의 키의 해싱해도 해시 충돌 발생 빈도 증가)
- 군집화된 값들을 순차적으로 방문하여 해시 성능이 크게 저하될 수 있다.
- 따라서, 선형 탐사법은 해시 충돌이 해시 값 전체에 균등하게 발생할 때 유용하다.
Quadratic Probing, 제곱 탐사법
- 충돌 확률을 줄일 대안으로 나온 것이 좀 더 멀리서 빈 공간을 찾자는 아이디어
- Linear Probing이 n 칸 옆의 슬롯을 검사한다면, Quadratic Probing은 충돌 발생시 n 제곱 칸 옆의 슬롯을 검사한다.
- Linear Probing : 고정 폭으로 증가시키며 탐색 (f(k) + n)
- Quadratic Probing : 폭을 제곱시키며 탐색 (f(k) + n^2)
[장점]
- 군집화 문제 해결
데이터의 밀집도가 선형 탐사법보다 낮기 때문에 다른 해시 값까지 영향을 받아 연쇄적 충돌 발생 가능성 적어진다.
[단점]
- 속도 저하 (선형 방식에 비해 캐시 성능 떨어짐) - 캐시 지역성 감소
CPU 캐시는 메모리 접근 패턴이 연속적일 수록 효율이 높다. 선형 탐사는 충돌 시 바로 옆 슬롯을 연속적으로 접근하기 때문에 공간 지역성이 좋았지만, 제곱 탐사 방식은 탐색 위치가 비연속적이고 멀리 퍼지게 되므로 캐시 효율이 떨어진다. (더 많은 캐시 미스 발생, 캐시 적중률 감소)
Double Hashing
- Quadratic Probing, Linear Probing에서 여전히 해결하지 못하는 문제
해시 충돌 발생 시 빈 슬롯을 찾기 위해 접근하는 위치가 동일하므로, 접근 슬롯을 중심으로 클러스터 현상 발생 확률은 여전히 높다. → 클러스터링 최소화 목적 - 충돌 발생 시 다른 해시 함수를 추가로 적용하여, 빈 슬롯을 찾는 간격을 불규칙하게 구성하는 방식
- 1차 해시 함수는 기존과 같이 키를 근거로 저장 위치를 결정, 2차 해시 함수는 충돌 발생 시 몇 칸 뒤에 저장할 지 결정한다.
[장점]
- 선형, 제곱 탐사보다 클러스터 발생 확률을 현저히 낮출 수 있다.
- 탐사 간격은 고정되지 않고 키에 따라 다르므로 충돌이 잘 퍼진다. (충돌 발생 가능선 가장 적음)
[단점]
- 탐색 위치가 불규칙하므로 선형, 제곱 탐사에 비해 캐시 성능은 떨어진다.
- 추가적인 해시 연산으로 가장 많은 연산량 요구 (해싱에 더 많은 시간 소요)
Separate Chaining, 분산 체이닝
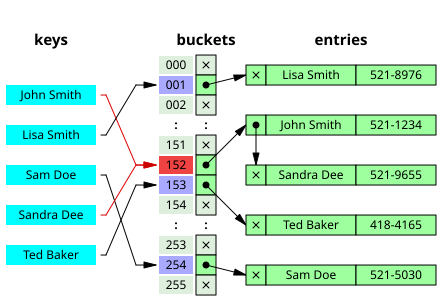 출처 : https://en.wikipedia.org/wiki/Hash_table
출처 : https://en.wikipedia.org/wiki/Hash_table
- 버킷 당 들어가는 엔트리 수에 제한을 두지 않고, 각 버킷에 연결 리스트 또는 트리 형태로 데이터를 저장한다.
Closed Addressing방법이라고도 하며, 해시 테이블에 추가적인 메모리를 사용한다.- 탐색 시간 복잡도 worst (모든 데이터가 같은 해시값을 가질 때) O(N), 버킷 사이즈 N
[장점]
- 구현이 간단하고 유연
- 동적으로 크기를 조절하기 쉽다.
[단점]
- Open Addressing에 비해 추가적인 메모리 공간 필요
- 버킷에 할당된 테이블이 놀고 있는 현상 (공간 낭비)
- 체인이 길어지면 탐색 시간 복잡도 증가
- 연결 리스트의 캐싱 성능 좋지 않다. (길이가 길어지면 탐색 시간이 길어질 수 있다.)
대신 레드-블랙 트리를 사용하여 충돌을 해결, 탐색 시간 개선할 수 있다.
비교
적재율이 작을 경우, Open Addressing 방식이 평균적으로 더 빠르다.
Open Addressing은 연속된 공간에 데이터를 저장하기 때문에 Separate Chaining에 비해 캐시 효율이 높다. 따라서, 데이터 개수가 적다면 Open Addressing 방식이 Separate Chaining 방식보다 효율이 좋다.
하지만, 저장되는 데이터가 많아지면 캐시 효율의 장점이 사라진다. (Separate Chaining보다 느려진다.) 데이터가 많아질수록 연속된 메모리를 탐색해야 하는 (Worst Case) 빈도가 높아져 캐시 적중률이 낮아지기 때문이다.
Separate Chaining 방식은 해시 충돌이 잘 발생하지 않도록 조정할 수 있다면 Worst Case에 가까운 일이 발생하는 것을 줄일 수 있다.시간 복잡도
해시 버킷 사이즈 N일 때, 두 방법 모두 Worst Case O(N)
Hashing with Buckets
동일한 해시에 하나 이상의 레코드를 저장할 수 있는 블럭을 의미
References
- https://superohinsung.tistory.com/113
- https://dkswnkk.tistory.com/679
- https://braindisk.tistory.com/m/107
- https://d2.naver.com/helloworld/831311
- https://runa-nam.tistory.com/84